
Laufzeit 01.01.2023-31.12.2023
Editionen als Linked Data
Wissenschaftliche Texteditionen stellen aufgrund vielfältiger Faktoren im Hinblick auf die sekundäre, übergreifende Auswertung und ihre Nachnutzbarkeit eine große Herausforderung dar. Diese umfassen sowohl die inhaltliche Zusammenstellung als auch Auswertung und Sicherung der erhobenen Daten. Zu den Herausforderungen gehören:
- unterschiedliche zeitliche und geographische Ausrichtungen der Forschungsinhalte
- verschiedene Sprachen und Sprachstufen
- unterschiedliche Schriftsysteme
- Präsentation in unterschiedlichen Kombinationen von Editionstext, Übersetzung, Faksimiles u.a.
- Digitale Daten liegen in unterschiedlichen Systemarchitekturen und Datenmodellen vor
- Veränderlichkeit der erhobenen Daten während der Laufzeit der Edition “hot data” (Erst die Langzeitarchivierung der Daten nach Projektabschluss “cold data” garantiert die Unveränderlichkeit der Daten.)
Das langfristige Zugänglichmachen von Forschungsdaten ist daher ein wesentliches Element wissenschaftlicher Forschung.
Das Projekt
Das Projekt "edition2LD" arbeitet an einer Lösung für eine Datenkuratierung, die heterogene Forschungsdaten langfristig und über die oben gelisteten Grenzen hinweg zugreifbar macht. Diese muss flexibel genug für die Heterogenität der Daten und zugleich stabil genug für eine langfristige Perspektive sein. Für die Lösung folgt das Projekt edition2LD dem Paradigma von Linked Data (LD) und der Integration der Daten ins Semantic Web.
Anwendungsfall als „Best Practice“
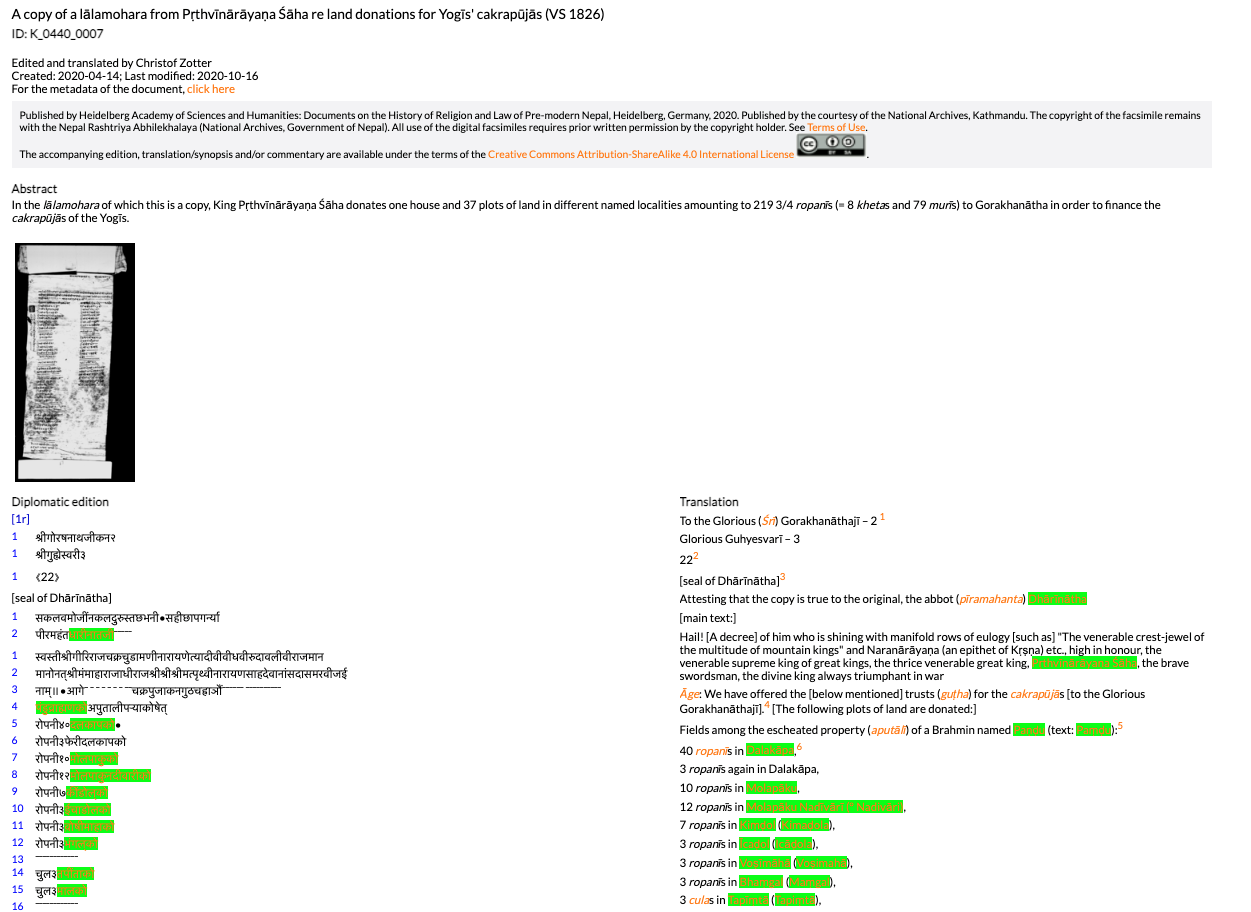
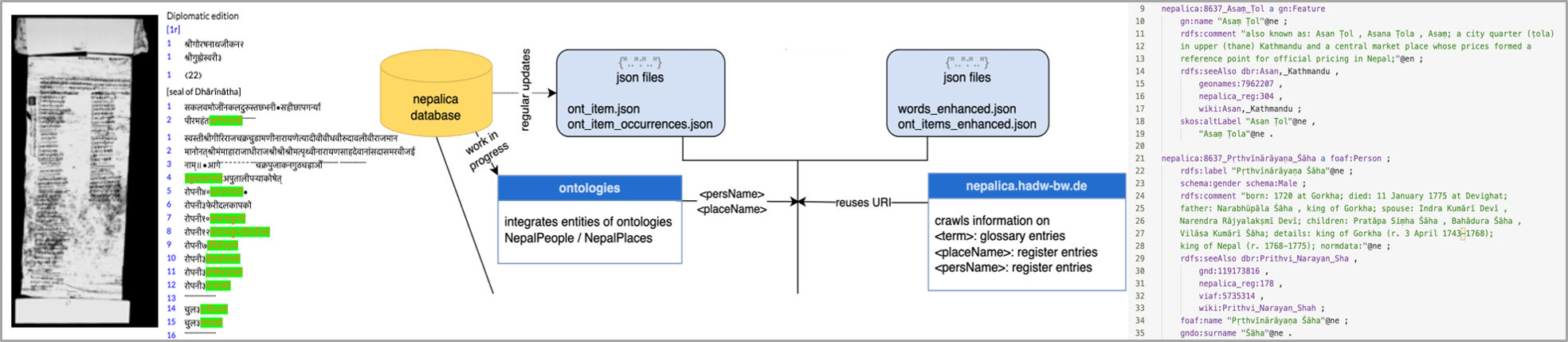
Um den Workflow für die Linked Data (LD)-Modellierung zu erarbeiten, wählt das Projekt als Anwendungsfall die Editionen der Forschungsstelle „Religions- und rechtsgeschichtliche Quellen des vormodernen Nepal“ (Nepal-FS) der HAdW. Die Forschungsstelle erstellt digitale Editionen der Nepali-Texte (in Devanagari-Schrift) inklusive Faksimiles, englische Übersetzungen (in lateinischer Schrift), Kommentare und Registereinträge (Personen, Orte, Fachtermini).
Publiziert wird auf nepalica.hadw-hw.de und unter Vergabe einer DOI auf den Seiten der Universitätsbibliothek Heidelberg (s. z.B. https://digi.hadw-bw.de/view/dna_0001_0005).
Herangehensweise
Der Workflow für die LD-Modellierung soll generisch genug sein, um die zukünftige Übertragbarkeit auf weitere Projekte vorzubereiten. Zugleich soll er in der Lage sein, um – wiederholt angestoßen – Daten chargenweise in RDF zu überführen und damit auf die große Herausforderung der veränderlichen “hot data” zu reagieren. Bei der Erarbeitung der automatisierten Abbildungsprozesse ist es daher immens wichtig, den Schritt einer händischen Nachbearbeitung zu minimieren, im besten Fall so, dass er nur einmal durchgeführt werden muss.
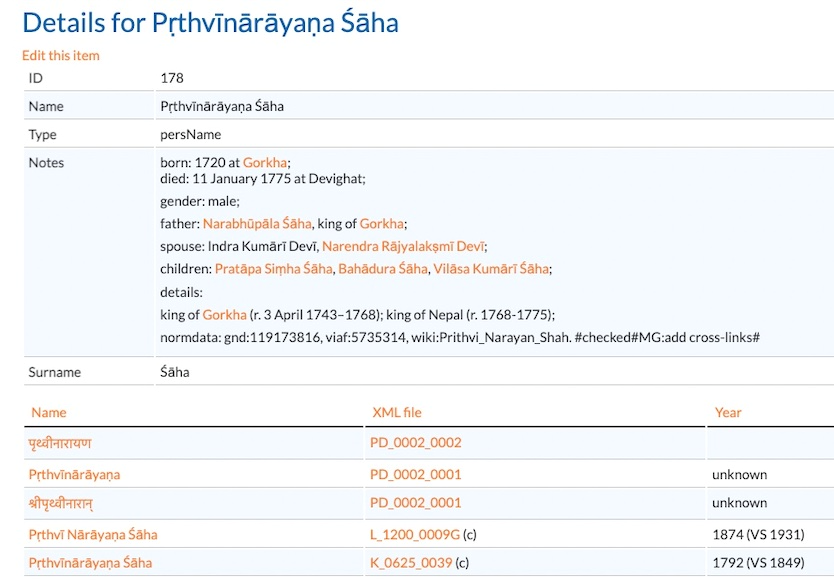
Das Projekt fokussiert auf die Modellierung der Informationseinheiten „Text“, „englische Übersetzung“, Named Entities (Personen- und Orstnamen) und Fachtermini sowie Metadaten. Für die Modellierung der Named Entities kann das Projekt auf Registereinträge der Nepal-FS zurückgreifen, die zum Teil bereits weiterführende Verweise auf Normdatenrepositorien und enzyklopädische Ressourcen enthalten.
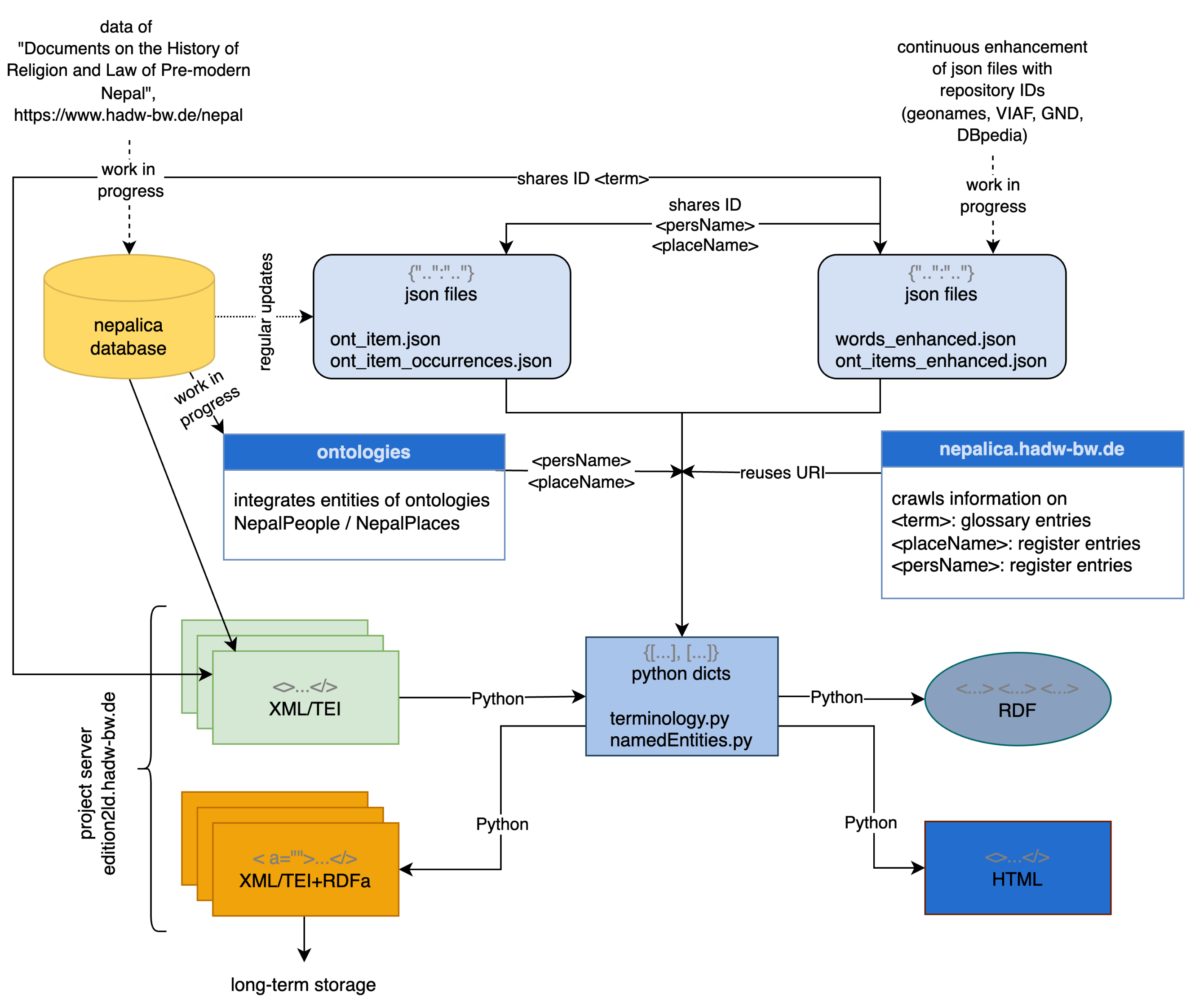
Die zur Modellierung eingesetzten Vokabulare, Ontologien und Repositorien sind die als Standards bereits etablierten: RDFS, SKOS, Gemeinsame Normdatei GND, VIAF, DBpedia, GeoNames, FOAF etc. Darüber hinaus fügt die LD-Modellierung Verlinkungen mit Instanzen zweier Ontologien für historische Personen- und Ortsnamen Nepals ein (NepalPeople und NepalPlaces, s. Tittel 2022*), die anhand der Forschungsdaten der Nepal-FS erarbeitet werden.
Die Datenquellen sind:
- die Datenbank der Nepal-FS
- Dateien mit weiterführenden Informationen
- Informationen, die aus den Register- und Glossareinträgen per Web Crawling in die Pipeline integriert werden
- Ontologien NepalPeople und NepalPlaces: Python-Skripte gleichen die modellierten Daten mit den Einträge von NepalPeople und NepalPlaces ab und integrieren gegebenenfalls Verlinkungen mit deren Instanzen.

Zum gegenwärtigen Stand [September 2023] ist die Modellierung der Named Entities und der Termini zu 90% abgeschlossen, die Modellierung der Einheiten „Englische Übersetzung“, „Nepali-Edition“ und der Metadaten ist in Arbeit.
Einen durchgehend bereits auf Linked Data aufbauenden Ansatz verfolgt das Projekt „Sprachdatenbasierte Modellierung von Wissensnetzen in der mittelalterlichen Romania – ALMA“ (interner Link), das als interakademisches Projekt der HAdW, BAdW und der AdW Mainz am 1. August 2022 im Akademienprogramm gestartet ist. Da ALMA Texteditionen (hier von mittelalterlichen Rechts- und Medizintexten) erarbeitet, lässt sich auch dieser Datenbestand gut für einen edition2LD-Ansatz einsetzen.
Publikationen
Svoboda-Baas, Dieta/Tittel, Sabine: Text+Plus, #04: Modellierung von Texteditionen als Linked Data (edition2LD), in: Text+ Blog, 18.12.2023, https://textplus.hypotheses.org/8723.
*Tittel, Sabine. "Towards an Ontology for Toponyms in Nepalese Historical Documents", in: Proceeding of the Workshop on Resources and Technologies for Indigenous, Endangered and Lesser-resourced Languages in Eurasia within the 13th Language Resources and Evaluation Conference, Marseille, June 2022, 2022, Marseille (European Language Resource Association - ELRA), S. 7-16.